
 • What is Data Warehouse ?
• What is Data Warehouse ?

When data warehouses first came onto the scene in the late 1980s, their purpose was to help data flow from operational systems into decision-support systems (DSSs). These early data warehouses required an enormous amount of redundancy. Most organizations had multiple DSS environments that served their various users. Although the DSS environments used much of the same data, the gathering, cleaning, and integration of the data was often replicated for each environment.
As data warehouses became more efficient, they evolved from information stores that supported traditional BI platforms into broad analytics infrastructures that support a wide variety of applications, such as operational analytics and performance management.
Data warehouse iterations have progressed over time to deliver incremental additional value to the enterprise.
- Transactional reporting:
- Provides relational information to create snapshots of business performance
- Slice and dice, ad hoc query, BI tools:
- Expands capabilities for deeper insights and more robust analysis
- Predicting future performance (data mining):
- Develops visualizations and forward-looking business intelligence
- Tactical analysis (spatial, statistics):
- Offers “what-if” scenarios to inform practical decisions based on more comprehensive analysis
- Stores many months or years of data:
- Stores data for only weeks or months
Supporting each of these five steps has required an increasing variety of datasets. The last three steps in particular create the imperative for an even broader range of data and analytics capabilities.
Today, AI and machine learning are transforming almost every industry, service, and enterprise asset—and data warehouses are no exception. The expansion of big data and the application of new digital technologies are driving change in data warehouse requirements and capabilities.
The autonomous data warehouse is the latest step in this evolution, offering enterprises the ability to extract even greater value from their data while lowering costs and improving data warehouse reliability and performance.
Find out more about autonomous data warehouses and get started with your own autonomous data warehouse.
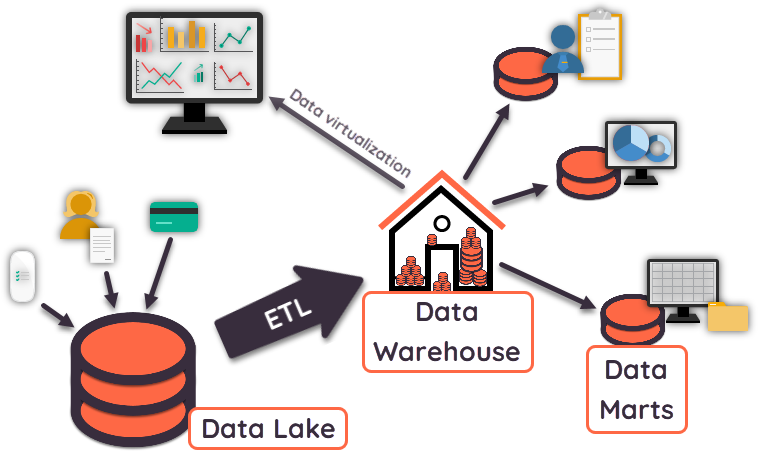
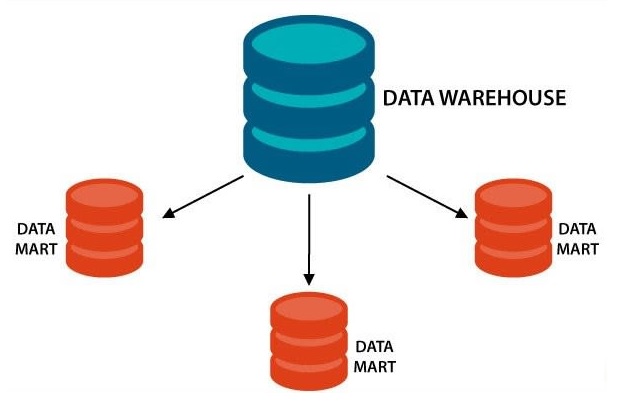
Data Warehouses, Data Marts, and Operation Data Stores
Though they perform similar roles, data warehouses are different from data marts and operation data stores (ODSs). A data mart performs the same functions as a data warehouse but within a much more limited scope—usually a single department or line of business. This makes data marts easier to establish than data warehouses. However, they tend to introduce inconsistency because it can be difficult to uniformly manage and control data across numerous data marts.
ODSs support only daily operations, so their view of historical data is very limited. Although they work very well as sources of current data and are often used as such by data warehouses, they do not support historically rich queries.

A cloud data warehouse uses the cloud to ingest and store data from disparate data sources.
The original data warehouses were built with on-premises servers. These on-premises data warehouses continue to have many advantages today. In many cases, they can offer improved governance, security, data sovereignty, and better latency. However, on-premises data warehouses are not as elastic and they require complex forecasting to determine how to scale the data warehouse for future needs. Managing these data warehouses can also be very complex.
On the other hand, some of the advantages of cloud data warehouses include:
- Elastic, scale-out support for large or variable compute or storage requirements
- Ease of use
- Ease of management
- Cost savings
The best cloud data warehouses are fully managed and self-driving, ensuring that even beginners can create and use a data warehouse with only a few clicks. An easy way to start your migration to a cloud data warehouse is to run your cloud data warehouse on-premises, behind your data center firewall which complies with data sovereignty and security requirements.
In addition, most cloud data warehouses follow a pay-as-you-go model, which brings added cost savings to customers.
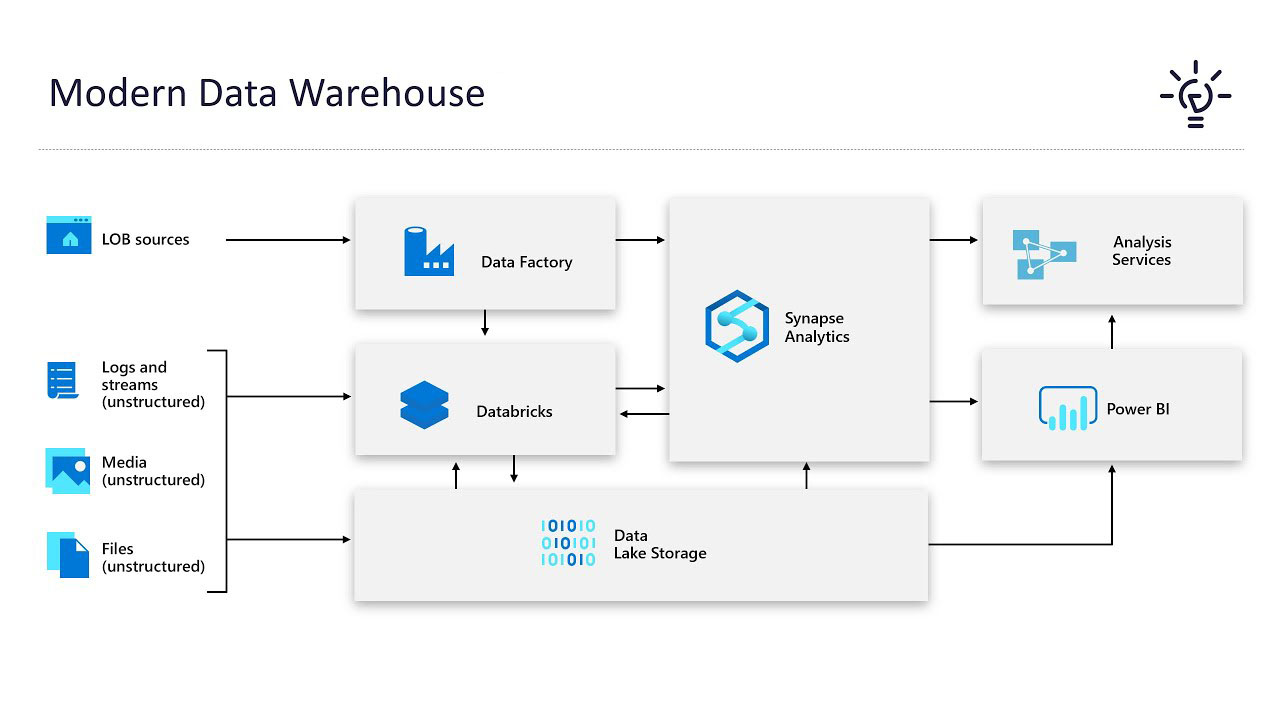
Whether they’re part of IT, data engineering, business analytics, or data science teams, different users across the organization have different needs for a data warehouse.
A modern data architecture addresses those different needs by providing a way to manage all data types, workloads, and analysis. It consists of architecture patterns with necessary components integrated to work together in alignment with industry best practices. The modern data warehouse includes:
- A converged database that simplifies management of all data types and provides different ways to use data
- Self-service data ingestion and transformation services
- Support for SQL, machine learning, graph, and spatial processing
- Multiple analytics options that make it easy to use data without moving it
- Automated management for simple provisioning, scaling, and administration
A modern data warehouse can efficiently streamline data workflows in a way that other warehouses can’t. This means that everyone, from analysts and data engineers to data scientists and IT teams, can perform their jobs more effectively and pursue the innovative work that moves the organization forward, without countless delays and complexity.
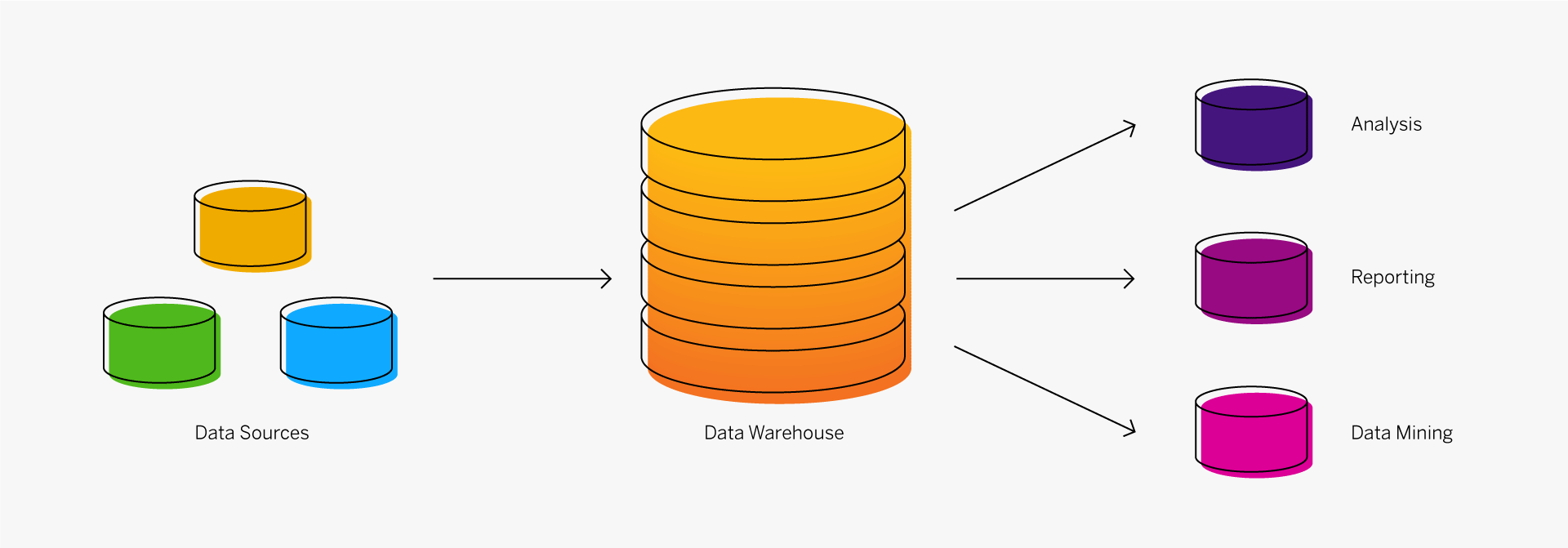
When an organization sets out to design a data warehouse, it must begin by defining its specific business requirements, agreeing on the scope, and drafting a conceptual design. The organization can then create both the logical and physical design for the data warehouse. The logical design involves the relationships between the objects, and the physical design involves the best way to store and retrieve the objects. The physical design also incorporates transportation, backup, and recovery processes.
Any data warehouse design must address the following:
- Specific data content
- Relationships within and between groups of data
- The systems environment that will support the data warehouse
- The types of data transformations required
- Data refresh frequency
A primary factor in the design is the needs of the end users. Most end users are interested in performing analysis and looking at data in aggregate, instead of as individual transactions. However, often end users don’t really know what they want until a specific need arises. Thus, the planning process should include enough exploration to anticipate needs. Finally, the data warehouse design should allow room for expansion and evolution to keep pace with the evolving needs of end users.
The Cloud and the Data Warehouse
Data warehouses in the cloud offer the same characteristics and benefits of on-premises data warehouses but with the added benefits of cloud computing―such as flexibility, scalability, agility, security, and reduced costs. Cloud data warehouses allow enterprises to focus solely on extracting value from their data rather than having to build and manage the hardware and software infrastructure to support the data warehouse.
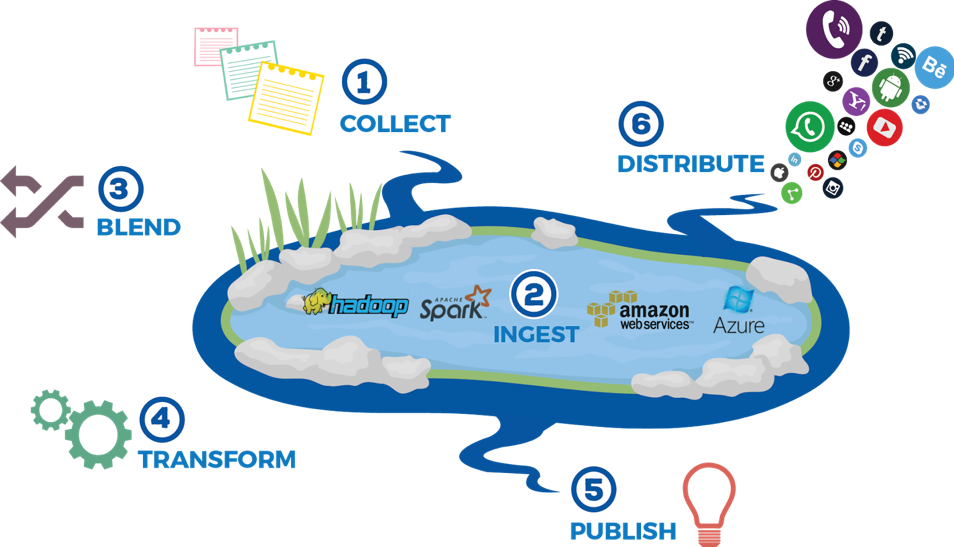
Organizations use both data lakes and data warehouses for large volumes of data from various sources. The choice of when to use one or the other depends on what the organization intends to do with the data. The following describes how each is best used:
- Data lakes store an abundance of disparate, unfiltered data to be used later for a particular purpose. Data from line-of-business applications, mobile apps, social media, IoT devices, and more is captured as raw data in a data lake. The structure, integrity, selection, and format of the various datasets is derived at the time of analysis by the person doing the analysis. When organizations need low-cost storage for unformatted, unstructured data from multiple sources that they intend to use for some purpose in the future, a data lake might be the right choice.
- Data warehouses are specifically intended to analyze data. Analytical processing within a data warehouse is performed on data that has been readied for analysis—gathered, contextualized, and transformed—with the purpose of generating analysis-based insights. Data warehouses are also adept at handling large quantities of data from various sources. When organizations need advanced data analytics or analysis that draws on historical data from multiple sources across their enterprise, a data warehouse is likely the right choice.
Data warehouses are relational environments that are used for data analysis, particularly of historical data. Organizations use data warehouses to discover patterns and relationships in their data that develop over time.
In contrast, transactional environments are used to process transactions on an ongoing basis and are commonly used for order entry and financial and retail transactions. They do not build on historical data; in fact, in OLTP environments, historical data is often archived or simply deleted to improve performance.
Data warehouses and OLTP systems differ significantly.
- Workload:
- Data Warehouse: Accommodates ad hoc queries and data analysis
- OLTP System: Supports only predefined operations
- Data modifications:
- Data Warehouse: Automatically updates on a regular basis
- OLTP System: Updates by end users issuing individual statements
- Schema design:
- Data Warehouse: Uses partially denormalized schemas to optimize performance
- OLTP System: Uses fully normalized schemas to guarantee data consistency
- Data scanning:
- Data Warehouse: Encompasses thousands to millions of rows
- OLTP System: Accesses only a handful of records at a time
- Historical data:
- Data Warehouse: Stores many months or years of data
- OLTP System: Stores data for only weeks or months
The most recent iteration of the data warehouse is the autonomous data warehouse, which relies on AI and machine learning to eliminate manual tasks and simplify setup, deployment, and data management. An as-a-service autonomous data warehouse in the cloud requires no human-performed database administration, hardware configuration or management, or software installation.
Creating the data warehouse, backing up, patching and upgrading the database, and expanding or reducing the database are all performed automatically—with the same flexibility, scalability, agility, and reduced costs that cloud platforms offer. The autonomous data warehouse removes complexity, speeds deployment, and frees up resources so organizations can focus on activities that add value to the business.
Oracle Autonomous Data Warehouse
Oracle Autonomous Data Warehouse is an easy-to-use, fully autonomous data warehouse that scales elastically, delivers fast query performance, and requires no database administration. The setup for Oracle Autonomous Data Warehouse is very simple and fast.
Why choose Oracle Autonomous Data Warehouse over Snowflake
- The only data warehouse fully automates database administration.
- Ease of use. The Autonomous Data Warehouse solution is simpler to deploy and manage with built-in capabilities that remove the need for additional standalone services
- Cost of solution. Our modern data warehouse and enhanced feature have similar costs to similar workload requirements.
- Data security.We provide stronger built-in security protocols that protects your data against cyber threats.
- Data governance. Our data warehouse platform makes it seamless for organizations to manage to data sovereignty needs.



